xAI Grok Imagine API - the #1 Video Model, Best Pricing and Latency - and merging with SpaceX

xAI cements its position as a frontier lab.
AI News for 1/28/2026-1/29/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (253 channels, and 7278 messages) for you. Estimated reading time saved (at 200wpm): 605 minutes. Our new website is now up with full metadata search and beautiful vibe coded presentation of all past issues. See https://news.smol.ai/ for the full news breakdowns and give us feedback on @smol_ai!
It looks like OpenAI (fundraising at around ~800b), Anthropic (worth $350b) and now SpaceX + xAI ($1100B? - folllowing their $20B Series E 3 weeks ago) are in a dead heat racing to IPO by year end. Google made an EXTREMELY strong play today launching Genie 3 (previously reported) to Ultra subscribers, and though technically impressive,, today’s headline story rightfully belongs to Grok, who now have the SOTA Image/Video Generation and Editing model released in API that you can use today.
Artificial Analysis’ rankings says it all:
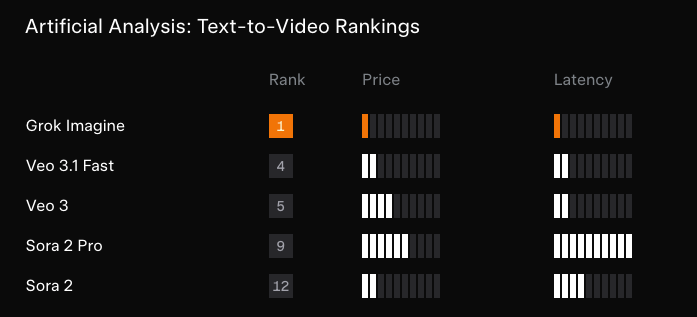
There’s not much else to say here apart from look at the list of small video model labs and wonder which of them just got bitter lessoned…
AI Twitter Recap
World Models & Interactive Simulation: Google DeepMind’s Project Genie (Genie 3) vs. Open-Source “World Simulators”
- Project Genie rollout (Genie 3 + Nano Banana Pro + Gemini): Google/DeepMind launched Project Genie, a prototype that lets users create and explore interactive, real-time generated worlds from text or image prompts, with remixing and a gallery. Availability is currently gated to Google AI Ultra subscribers in the U.S. (18+), and the product is explicit about prototype limitations (e.g., ~60s generation limits, control latency, imperfect physics adherence) (DeepMind announcement, how it works, rollout details, Demis, Sundar, Google thread, Google limitations). Early-access testers highlight promptability, character/world customization, and “remixing” as key UX hooks (venturetwins, Josh Woodward demo thread).
- Open-source push: LingBot-World: A parallel thread frames world models as distinct from “video dreamers,” arguing for interactivity, object permanence, and causal consistency. LingBot-World is repeatedly described as an open-source real-time interactive world model built on Wan2.2 with <1s latency at 16 FPS and minute-level coherence (claims include VBench improvements and landmark persistence after long occlusion) (paper-summary thread, HuggingPapers mention, reaction clip). The meta-narrative: proprietary systems (Genie) are shipping consumer prototypes while open systems race to close capability gaps on coherence + control.
Video Generation & Creative Tooling: xAI Grok Imagine, Runway Gen-4.5, and fal’s “Day-0” Platforms
- xAI Grok Imagine (video + audio) lands near/at the top of leaderboards: Multiple sources report Grok Imagine’s strong debut in video rankings and emphasize native audio, 15s duration, and aggressive pricing ($4.20/min including audio) relative to Veo/Sora (Arena launch ranking, Artificial Analysis #1 claim + pricing context, follow-up #1 I2V leaderboard, xAI team announcement, Elon). fal positioned itself as day-0 platform partner with API endpoints for text-to-image, editing, text-to-video, image-to-video, and video editing (fal partnership, fal links tweet).
- Runway Gen-4.5 shifts toward “animation engine” workflows: Creators describe Gen-4.5 as increasingly controllable for animation-style work (c_valenzuelab). Runway shipped Motion Sketch (annotate camera/motion on a start frame) and Character Swap as built-in apps—more evidence that vendors are packaging controllability primitives rather than only pushing base quality (feature thread). Runway also markets “photo → story clip” flows as a mainstream onramp (Runway example).
- 3D generation joins the same API distribution layer: fal also added Hunyuan 3D 3.1 Pro/Rapid (text/image-to-3D, topology/part generation), showing the same “model-as-a-service + workflow endpoints” pattern spreading from image/video into 3D pipelines (fal drop).
Open Models & Benchmarks: Kimi K2.5 momentum, Qwen3-ASR release, and Trinity Large architecture details
- Kimi K2.5 as the “#1 open model” across multiple eval surfaces: Moonshot promoted K2.5’s rank on VoxelBench (Moonshot) and later Kimi updates focus on productization: Kimi Code now powered by K2.5, switching from request limits to token-based billing, plus a limited-time 3× quota/no throttling event (Kimi Code billing update, billing rationale). Arena messaging amplifies K2.5 as a leading open model with forthcoming Code Arena scores (Arena deep dive, Code Arena prompt); Arena also claims Kimi K2.5 Thinking as #1 open model in Vision Arena and the only open model in the top 15 (Vision Arena claim). Commentary frames K2.5 as “V3-generation architecture pushed with more continued training,” with next-gen competition expected from K3/GLM-5 etc. (teortaxes).
- Alibaba Qwen3-ASR: production-grade open speech stack with vLLM day-0 support: Qwen released Qwen3-ASR + Qwen3-ForcedAligner emphasizing messy real-world audio, 52 languages/dialects, long audio (up to 20 minutes/pass), and timestamps; models are Apache 2.0 and include an open inference/finetuning stack. vLLM immediately announced day-0 support and performance notes (e.g., “2000× throughput on 0.6B” in their tweet) (Qwen release, ForcedAligner, vLLM support, Adina Yakup summary, native streaming claim, Qwen thanks vLLM). Net: open-source speech is increasingly “full-stack,” not just weights.
- Arcee AI Trinity Large (400B MoE) enters the architecture discourse: Multiple threads summarize Trinity Large as 400B MoE with ~13B active, tuned for throughput via sparse expert selection, and featuring a grab bag of modern stability/throughput techniques (router tricks, load balancing, attention patterns, normalization variants). Sebastian Raschka’s architecture recap is the most concrete single reference point (rasbt); additional MoE/router stability notes appear in a separate technical summary (cwolferesearch). Arcee notes multiple variants trending on Hugging Face (arcee_ai).
Agents in Practice: “Agentic Engineering,” Multi-Agent Coordination, and Enterprise Sandboxes
- From vibe coding to agentic engineering: A high-engagement meme-like anchor tweet argues for “Agentic Engineering > Vibe Coding” and frames professionalism around repeatable workflows rather than vibes (bekacru). Several threads reinforce the same theme operationally: context prep, evaluations, and sandboxing as the hard parts.
- Primer: repo instructions + lightweight evals + PR automation: Primer proposes a workflow for “AI-enabling” repos: agentic repo introspection → generate an instruction file → run a with/without eval harness → scale via batch PRs across org repos (Primer launch, local run, eval framework, org scaling).
- Agent sandboxes + traceability as infra primitives: Multiple tweets point to “agent sandboxes” (isolated execution environments) as an emerging January trend (dejavucoder). Cursor proposed an open standard to trace agent conversations to generated code, explicitly positioning it as interoperable across agents/interfaces (Cursor). This pairs with broader ecosystem pressure: agents need auditability and reliable grounding when they can take actions.
- Multi-agent coordination beats “bigger brain” framing: A popular summary claims a system that uses a controller trained by RL to route between large/small models can beat a single large agent on HLE with lower cost/latency—reinforcing that orchestration policies are becoming first-class artifacts (LiorOnAI). In the same direction, an Amazon “Insight Agents” paper summary argues for pragmatic manager-worker designs with lightweight OOD detection and routing (autoencoder + fine-tuned BERT) instead of LLM-only classifiers for latency/precision reasons (omarsar0).
- Kimi’s “Agent Swarm” philosophy: A long-form repost from ZhihuFrontier describes K2.5’s agent mode as a response to “text-only helpfulness” and tool-call hallucinations, emphasizing planning→execution bridging, dynamic tool-based context, and multi-viewpoint planning via swarms (ZhihuFrontier).
- Moltbot/Clawdbot safety trilemma: Community discussion frames “Useful vs Autonomous vs Safe” as a tri-constraint until prompt injection is solved (fabianstelzer). Another take argues capability (trust) bottlenecks dominate: users won’t grant high-stakes autonomy (e.g., finance) until agents are reliably competent (Yuchenj_UW).
Model UX, DevTools, and Serving: Gemini Agentic Vision, OpenAI’s in-house data agent, vLLM fixes, and local LLM apps
- Gemini 3 Flash “Agentic Vision”: Google positions Agentic Vision as a structured image-analysis pipeline: planning steps, zooming, annotating, and optionally running Python for plotting—essentially turning “vision” into an agentic workflow rather than a single forward pass (GeminiApp intro, capabilities, rollout note).
- OpenAI’s in-house data agent at massive scale: OpenAI described an internal “AI data agent” reasoning over 600+ PB and 70k datasets, using Codex-powered table knowledge and careful context management (OpenAIDevs). This is a rare concrete peek at “deep research/data agent” architecture constraints: retrieval + schema/table priors + org context.
- Serving bugs are still real (vLLM + stateful models): AI21 shared a debugging story where scheduler token allocation caused misclassification between prefill vs decode, now fixed in vLLM v0.14.0—a reminder that infrastructure correctness matters, especially for stateful architectures like Mamba (AI21Labs thread).
- Local LLM UX continues to improve: Georgi Gerganov shipped LlamaBarn, a tiny macOS menu bar app built on llama.cpp to run local models (ggerganov). Separate comments suggest agentic coding performance may improve by disabling “thinking” modes for specific models (GLM-4.7-Flash) via llama.cpp templates (ggerganov config note).
Top tweets (by engagement)
- Grok Imagine hype & distribution: @elonmusk, @fal, @ArtificialAnlys
- DeepMind/Google world models: @GoogleDeepMind, @demishassabis, @sundarpichai
- AI4Science: @demishassabis on AlphaGenome
- Speech open-source release: @Alibaba_Qwen Qwen3-ASR
- Agents + developer workflow: @bekacru “Agentic Engineering > Vibe Coding”, @cursor_ai agent-trace.dev
- Anthropic workplace study: @AnthropicAI AI-assisted coding and mastery
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Kimi K2.5 Model Discussions and Releases
-
AMA With Kimi, The Open-source Frontier Lab Behind Kimi K2.5 Model (Activity: 686): Kimi is the research lab behind the open-source Kimi K2.5 model, engaging in an AMA to discuss their work. The discussion highlights a focus on large-scale models, with inquiries about the development of smaller models like
8B,32B, and70Bfor better intelligence density. There is also interest in smaller Mixture of Experts (MoE) models, such as~100Btotal with~A3Bactive, optimized for local or prosumer use. The team is questioned on their stance regarding the notion that Scaling Laws have hit a wall, a topic of current debate in AI research. Commenters express a desire for smaller, more efficient models, suggesting that these could offer better performance for specific use cases. The debate on scaling laws reflects a broader concern in the AI community about the limits of current model scaling strategies.- The discussion around model sizes highlights a preference for smaller models like 8B, 32B, and 70B due to their 'intelligence density.' These sizes are considered optimal for balancing performance and resource efficiency, suggesting a demand for models that can operate effectively on limited hardware while still providing robust capabilities.
- The inquiry into smaller Mixture of Experts (MoE) models, such as a ~100B total with ~A3B active, indicates interest in models optimized for local or prosumer use. This reflects a trend towards developing models that are not only powerful but also accessible for individual users or small enterprises, emphasizing the need for efficient resource utilization without sacrificing performance.
- The challenge of maintaining non-coding abilities like creative writing and emotional intelligence in models like Kimi 2.5 is significant, especially as coding benchmarks become more prominent. The team is tasked with ensuring these softer skills do not regress, which involves balancing the training focus between technical and creative capabilities to meet diverse user needs.
-
Run Kimi K2.5 Locally (Activity: 553): The image provides a guide for running the Kimi-K2.5 model locally, emphasizing its state-of-the-art (SOTA) performance in vision, coding, agentic, and chat tasks. The model, which is a
1 trillionparameter hybrid reasoning model, requires600GBof disk space, but the quantized Unsloth Dynamic 1.8-bit version reduces this requirement to240GB, a60%reduction. The guide includes instructions for usingllama.cppto load models and demonstrates generating HTML code for a simple game. The model is available on Hugging Face and further documentation can be found on Unsloth's official site. Commenters discuss the feasibility of running the model on high-end hardware, with one user questioning its performance on a Strix Halo setup and another highlighting the substantial VRAM requirements, suggesting that only a few users can realistically run it locally.- Daniel_H212 is inquiring about the performance of the Kimi K2.5 model on the Strix Halo hardware, specifically asking for the token generation speed in seconds per token. This suggests a focus on benchmarking the model's efficiency on high-end hardware setups.
- Marksta provides feedback on the quantized version of the Kimi K2.5 model, specifically the Q2_K_XL variant. They note that the model maintains high coherence and adheres strictly to prompts, which is characteristic of Kimi-K2's style. However, they also mention that while the model's creative capabilities have improved, it still struggles with execution in creative scenarios, often delivering logical but poorly written responses.
- MikeRoz questions the utility of higher quantization levels like Q5 and Q6 (e.g., UD-Q5_K_XL, Q6_K) when most experts prefer int4 quantization. This highlights a debate on the trade-offs between model size, performance, and precision in quantization strategies.
-
Kimi K2.5 is the best open model for coding (Activity: 1119): The image highlights Kimi K2.5 as the leading open model for coding on the LMARENA.AI leaderboard, ranked
#7overall. This model is noted for its superior performance in coding tasks compared to other open models. The leaderboard provides a comparative analysis of various AI models, showcasing their ranks, scores, and confidence intervals, emphasizing Kimi K2.5's achievements in the coding domain. One commenter compared Kimi K2.5's performance to other models, noting it is on par with Sonnet 4.5 in accuracy but not as advanced as Opus in agentic function. Another comment criticized LMArena for not reflecting a model's multi-turn or long context capabilities.- A user compared Kimi K2.5 to other models, noting that it performs on par with Sonnet 4.5 in terms of accuracy for React projects, but not at the level of Opus in terms of agentic function. They also mentioned that Kimi 2.5 surpasses GLM 4.7, which was their previous choice, and expressed curiosity about the upcoming GLM-5 from z.ai.
- Another commenter criticized LMArena, stating that it fails to provide insights into a model's multi-turn, long context, or agentic capabilities, implying that such benchmarks are insufficient for evaluating comprehensive model performance.
- A user highlighted the cost-effectiveness of Kimi K2.5, stating it feels as competent as Opus 4.5 while being significantly cheaper, approximately 1/5th the cost, and even less expensive than Haiku. This suggests a strong performance-to-cost ratio for Kimi K2.5.
-
Finally We have the best agentic AI at home (Activity: 464): The image is a performance comparison chart of various AI models, including Kimi K2.5, GPT-5.2 (xhigh), Claude Opus 4.5, and Gemini 3 Pro. Kimi K2.5 is highlighted as the top-performing model across multiple categories such as agents, coding, image, and video tasks, indicating its superior capabilities in multimodal applications. The post suggests excitement about integrating this model with a 'clawdbot', hinting at potential applications in robotics or automation. A comment humorously suggests that hosting the Kimi 2.5 1T+ model at home implies having a large home, indicating the model's likely high computational requirements. Another comment sarcastically mentions handling it with a 16GB VRAM card, implying skepticism about the feasibility of running such a model on typical consumer hardware.
2. Open Source Model Innovations
-
LingBot-World outperforms Genie 3 in dynamic simulation and is fully Open Source (Activity: 230): The open-source framework LingBot-World surpasses the proprietary Genie 3 in dynamic simulation capabilities, achieving
16 FPSand maintaining object consistency for60 secondsoutside the field of view. This model, available on Hugging Face, offers enhanced handling of complex physics and scene transitions, challenging the monopoly of proprietary systems by providing full access to its code and model weights. Commenters question the hardware requirements for running LingBot-World and express skepticism about the comparison with Genie 3, suggesting a lack of empirical evidence or direct access to Genie 3 for a fair comparison.- A user questioned the hardware requirements for running LingBot-World, highlighting the importance of specifying computational needs for practical implementation. This is crucial for users to understand the feasibility of deploying the model in various environments.
- Another commenter raised concerns about the lack of a direct comparison with Genie 3, suggesting that without empirical data or benchmarks, claims of LingBot-World's superiority might be unsubstantiated. This points to the need for transparent and rigorous benchmarking to validate performance claims.
- A suggestion was made to integrate a smaller version of LingBot-World into a global illumination stack, indicating potential applications in graphics and rendering. This could leverage the model's capabilities in dynamic simulation to enhance visual computing tasks.
-
API pricing is in freefall. What's the actual case for running local now beyond privacy? (Activity: 1053): The post discusses the rapidly decreasing costs of API access for AI models, with examples like K2.5 offering prices at
10%of Opus and Deepseek being nearly free. Gemini also provides a substantial free tier. This trend is contrasted with the challenges of running large models locally, such as the need for expensive GPUs or dealing with quantization tradeoffs, which result in slow processing speeds (15 tok/s) on consumer hardware. The author questions the viability of local setups given these API pricing trends, noting that while privacy and latency control are valid reasons, the cost-effectiveness of local setups is diminishing. Commenters highlight concerns about the sustainability of low API prices, suggesting they may rise once market dominance is achieved, similar to past trends in other industries. Others emphasize the importance of offline capabilities and the ability to audit and trust local models, which ensures consistent behavior without unexpected changes from vendors.- Minimum-Vanilla949 highlights the importance of offline capabilities for those who travel frequently, emphasizing the risk of API companies altering terms of service or increasing prices once they dominate the market. This underscores the value of local models for ensuring consistent access and cost control.
- 05032-MendicantBias discusses the unsustainable nature of current API pricing, which is often subsidized by venture capital. They argue that once a monopoly is achieved, prices will likely increase, making local setups and open-source tools a strategic defense against such business models.
- IactaAleaEst2021 points out the importance of repeatability and trust in using local models. By downloading and auditing a model, users can ensure consistent behavior, unlike APIs where vendors might change model behavior over time, potentially reducing its utility for specific tasks.
3. Trends in AI Agent Frameworks
-
GitHub trending this week: half the repos are agent frameworks. 90% will be dead in 1 week. (Activity: 538): The image highlights a trend on GitHub where many of the trending repositories are related to AI agent frameworks, suggesting a surge in interest in these tools. However, the post's title and comments express skepticism about the sustainability of this trend, comparing it to the rapid rise and fall of JavaScript frameworks. The repositories are mostly written in Python and include a mix of agent frameworks, RAG tooling, and model-related projects like NanoGPT and Grok. The discussion reflects a concern that many of these projects may not maintain their popularity or relevance over time. One comment challenges the claim that half of the trending repositories are agent frameworks, noting that only one is an agent framework by Microsoft, while others are related to RAG tooling and model development. Another comment appreciates the utility of certain projects, like IPTV, for educational purposes.
- gscjj points out that the claim about 'half the repos being agent frameworks' is inaccurate. They note that the list includes a variety of projects such as Microsoft's agent framework, RAG tooling, and models like NanoGPT and Grok, as well as a model CLI for code named Kimi and a browser API. This suggests a diverse range of trending repositories rather than a dominance of agent frameworks.
-
Mistral CEO Arthur Mensch: “If you treat intelligence as electricity, then you just want to make sure that your access to intelligence cannot be throttled.” (Activity: 357): Arthur Mensch, CEO of Mistral, advocates for open-weight models, likening intelligence to electricity, emphasizing the importance of unrestricted access to AI capabilities. This approach supports the deployment of models on local devices, reducing costs as models are quantized for lower compute environments, contrasting with closed models that are often large and monetized through paywalls. Mistral aims to balance corporate interests with open access, potentially leading to significant breakthroughs in AI deployment. Commenters appreciate Mistral's approach to open models, noting the potential for reduced costs and increased accessibility. There is a consensus that open models could democratize AI usage, contrasting with the restrictive nature of closed models.
- RoyalCities highlights the cost dynamics of model deployment, noting that open models, especially when quantized, reduce costs as they can be run on local devices. This contrasts with closed models that are often large and require significant infrastructure, thus being monetized through paywalls. This reflects a broader industry trend where open models aim to democratize access by lowering hardware requirements.
- HugoCortell points out the hardware bottleneck in deploying open models effectively. While open-source models can rival closed-source ones in performance, the lack of affordable, high-performance hardware limits their accessibility. This is compounded by large companies making high-quality local hardware increasingly expensive, suggesting a need for a company capable of producing and distributing its own hardware to truly democratize AI access.
- tarruda expresses anticipation for the next open Mistral model, specifically the "8x22". This indicates a community interest in the technical specifications and potential performance improvements of upcoming models, reflecting the importance of open model development in advancing AI capabilities.
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. OpenAI and AGI Investments
-
Nearly half of the Mag 7 are reportedly betting big on OpenAI’s path to AGI (Activity: 1153): NVIDIA, Microsoft, and Amazon are reportedly in discussions to invest a combined total of up to
$60 billioninto OpenAI, with SoftBank considering an additional$30 billion. This potential investment could value OpenAI at approximately$730 billionpre-money, aligning with recent valuation discussions in the$750 billion to $850 billion+range. This would mark one of the largest private capital raises in history, highlighting the significant financial commitment from major tech companies towards the development of artificial general intelligence (AGI). Commenters note the strategic alignment of these investments, with one pointing out that companies like Microsoft and NVIDIA are unlikely to invest in competitors like Google. Another comment reflects on the evolving landscape of large language models (LLMs) and the shifting focus of tech giants.- CoolStructure6012 highlights the strategic alignment between Microsoft (MSFT) and NVIDIA (NVDA) with OpenAI, suggesting that their investments are logical given their competitive stance against Google. This reflects the broader industry trend where tech giants are aligning with AI leaders to bolster their AI capabilities and market positions.
- drewc717 reflects on the evolution of AI models, noting a significant productivity boost with OpenAI's
4.1 Pro mode. However, they express a decline in their workflow efficiency after switching to Gemini, indicating that not all LLMs provide the same level of user experience or productivity, which is crucial for developers relying on these tools. - EmbarrassedRing7806 questions the lack of attention on Anthropic despite its widespread use in coding through its Claude model, as opposed to OpenAI's Codex. This suggests a potential underestimation of Anthropic's impact in the AI coding space, where Claude might be offering competitive or superior capabilities.
2. DeepMind's AlphaGenome Launch
-
Google DeepMind launches AlphaGenome, an AI model that analyzes up to 1 million DNA bases to predict genomic regulation (Activity: 427): Google DeepMind has introduced AlphaGenome, a sequence model capable of analyzing up to
1 million DNA basesto predict genomic regulation, as detailed in Nature. The model excels in predicting genomic signals such as gene expression and chromatin structure, particularly in non-coding DNA, which is crucial for understanding disease-associated variants. AlphaGenome outperforms existing models on25 of 26benchmark tasks and is available for research use, with its model and weights accessible on GitHub. Commenters highlight the model's potential impact on genomics, with some humorously suggesting its significance in advancing scientific achievements akin to winning Nobel prizes. -
[R] AlphaGenome: DeepMind's unified DNA sequence model predicts regulatory variant effects across 11 modalities at single-bp resolution (Nature 2026) (Activity: 66): DeepMind's AlphaGenome introduces a unified DNA sequence model that predicts regulatory variant effects across
11 modalitiesat single-base-pair resolution. The model processes1M base pairsof DNA to predict thousands of functional genomic tracks, matching or exceeding specialized models in25 of 26evaluations. It employs a U-Net backbone with CNN and transformer layers, trained on human and mouse genomes, and captures99%of validated enhancer-gene pairs within a1Mbcontext. Training on TPUv3 took4 hours, with inference under1 secondon H100. The model demonstrates cross-modal variant interpretation, notably on the TAL1 oncogene in T-ALL. Nature, bioRxiv, DeepMind blog, GitHub. Some commenters view the model as an incremental improvement over existing sequence models, questioning the novelty despite its publication in Nature. Others express concerns about the implications of open-sourcing such powerful genomic tools, hinting at potential future applications like 'text to CRISPR' models.- st8ic88 argues that while DeepMind's AlphaGenome model is notable for its ability to predict regulatory variant effects across 11 modalities at single-base pair resolution, it is seen as an incremental improvement over existing sequence models predicting genomic tracks. The comment suggests that the model's prominence is partly due to DeepMind's reputation and branding, particularly the use of 'Alpha' in its name, which may have contributed to its publication in Nature.
- --MCMC-- is interested in the differences between the AlphaGenome model's preprint and its final published version in Nature. The commenter had read the preprint and is curious about any changes made during the peer review process, which could include updates to the model's methodology, results, or interpretations.
- f0urtyfive raises concerns about the potential risks of open-sourcing powerful genomic models like AlphaGenome, speculating on future developments such as 'text to CRISPR' models. This comment highlights the ethical and safety considerations of making advanced genomic prediction tools widely accessible, which could lead to unintended applications or misuse.
3. Claude's Cost Efficiency and Usage Strategies
-
Claude Subscriptions are up to 36x cheaper than API (and why "Max 5x" is the real sweet spot) (Activity: 665): A data analyst has reverse-engineered Claude's internal usage limits by analyzing unrounded floats in the web interface, revealing that subscriptions can be up to 36x cheaper than using the API, especially for coding tasks with agents like Claude Code. The analysis shows that the subscription model offers free cache reads, whereas the API charges 10% of the input cost for each read, making the subscription significantly more cost-effective for long sessions. The "Max 5x" plan at
$100/monthis highlighted as the most optimized, offering a6xhigher session limit and8.3xhigher weekly limit than the Pro plan, contrary to the marketed "5x" and "20x" plans. The findings were derived using the Stern-Brocot tree to decode precise usage percentages into internal credit numbers. Full details and formulas are available here. Commenters express concern over Anthropic's lack of transparency and speculate that the company might change the limits once they realize users have reverse-engineered them. Some users are taking advantage of the current subscription benefits, anticipating potential changes.- HikariWS raises a critical point about Anthropic's lack of transparency regarding their subscription limits, which could change unexpectedly, rendering current analyses obsolete. This unpredictability poses a risk for developers relying on these plans for cost-effective usage.
- Isaenkodmitry discusses the potential for Anthropic to close loopholes once they realize users are exploiting subscription plans for cheaper access compared to the API. This highlights a strategic risk for developers who are currently benefiting from these plans, suggesting they should maximize usage while it lasts.
- Snow30303 mentions using Claude code in VS Code for Flutter apps, noting that it consumes credits rapidly. This suggests a need for more efficient usage strategies or alternative solutions to manage costs effectively when integrating Claude into development workflows.
-
We reduced Claude API costs by 94.5% using a file tiering system (with proof) (Activity: 603): The post describes a file tiering system that reduces Claude API costs by 94.5% by categorizing files into HOT, WARM, and COLD tiers, thus minimizing the number of tokens processed per session. This system, implemented in a tool called
cortex-tms, tags files based on their relevance and usage frequency, allowing only the most necessary files to be loaded by default. The approach has been validated through a case study on the author's project, showing a reduction from66,834to3,647tokens per session, significantly lowering costs from$0.11to$0.01per session with Claude Sonnet 4.5. The tool is open-source and available on GitHub. One commenter inquired about the manual process of tagging files and updating tags, suggesting the use of git history to automate file heat determination. Another user appreciated the approach due to their own struggles with managing API credits.- Illustrious-Report96 suggests using
git historyto determine file 'heat', which involves analyzing the frequency and recency of changes to classify files as 'hot', 'warm', or 'cold'. This method leverages version control metadata to automate the classification process, potentially reducing manual tagging efforts. - Accomplished_Buy9342 inquires about restricting access to 'WARM' and 'COLD' files, which implies a need for a mechanism to control agent access based on file tier. This could involve implementing access controls or modifying the agent's logic to prioritize 'HOT' files, ensuring efficient resource usage.
- durable-racoon asks about the process of tagging files and updating these tags, highlighting the importance of an automated or semi-automated system to manage file tiering efficiently. This could involve scripts or tools that dynamically update file tags based on usage patterns or other criteria.
- Illustrious-Report96 suggests using
AI Discord Recap
A summary of Summaries of Summaries by Gemini 3.0 Pro Preview Nov-18
Theme 1. Model Wars: Kimi’s Rise, Recursive Agents, and Geometric Architectures
- Kimi K2.5 crushes the Vision Arena: The community reports Kimi K2.5 is dominating the leaderboards, claiming the #1 open model spot and ranking #6 overall on the Vision Arena leaderboard. Users note it outperforms Claude in specific vision tasks and now features a dedicated computer use model that handles phone screenshots (though it throws 403 errors on mobile uploads).
- Recursive Language Models trigger semantic debates: A heated discussion erupted over the term "Recursive Language Models" (RLM), with critics arguing it simply rebrands tool-calling loops, while proponents point to the new RLM-Qwen3-8B as the first natively recursive model. This small-scale model, post-trained on just 1,000 trajectories, reportedly beats scaffolded RLM versions in long-context tasks.
- Geometric Convolution attempts to dethrone Attention: Researchers are experimenting with a baseline that replaces standard Multi-Head Attention with a geometric convolution approach, using embeddings as cell connections. Early debug prints show loss convergence capturing dialogue logic, positioning this as a potential alternative to heavy transformer compute.
Theme 2. Hardware Hustle: Microsoft’s Silicon, Unsloth Speeds, and Apple’s Hidden Power
- Microsoft aims at NVIDIA with Maia 200: Microsoft unveiled the Maia 200 AI Accelerator, an inference-focused chip boasting 216GB of memory and 10k TFLOPS in FP4 performance. Engineers debated the reliance on TSMC manufacturing and compared its architecture favorably against NVIDIA's Vera Rubin for large-scale inference workloads.
- RTX 5090 shreds training benchmarks: Unsloth users report the RTX 5090 achieves blistering training speeds of up to 18k tokens per second, though 12-15k t/s is safer with a sequence length under 4096. Optimal throughput requires carefully balancing batch size and sequence length to avoid memory bottlenecks during fine-tuning.
- Apple’s ANE punches above its weight: A new discussion around this paper highlights that Apple's Neural Engine (ANE) delivers 3.8 TFlops on the M4-Pro, nearly matching the GPU's 4.7 TFlops for GEMM operations. The ANE prioritizes performance-per-watt, making it a surprisingly viable target for efficient local inference.
Theme 3. Dev Tools & Standards: Cursor Pains, MCP Security, and Parallel Studio
- Cursor’s "Plan Mode" annoys the power users: The latest Cursor update introduced a plan mode that users are actively trying to disable or automate, citing wasted time and unnecessary inputs. Fresh installs of the IDE are reportedly the most unstable configuration, driving users to seek workarounds for the "Plan Mode" friction.
- MCP gets a hardened Security Standard: Dani (cr0hn) drafted an open MCP Security Standard covering hardening, logging, and access control, intending to donate it to the Agentic AI Foundation. Simultaneously, the protocol is evolving with Namespaces being rejected in favor of Groups, detailed in the new Primitive Grouping SEP-2084.
- LM Studio 0.4 hides power tools behind Dev Mode: The release of LM Studio 0.4.0 tucks critical settings like sampling and hardware configs behind a Dev Mode toggle (
Ctrl+Shift+R), while introducing parallel requests. Users can now load models across different GPUs to handle up to 4 parallel requests by default, though the software still relies on the older ROCm 6.4.1.
Theme 4. Jailbreaks & Exploits: Keygens, "Remember" Hacks, and Malware Classifiers
- Gemini 3 Pro tricked into writing KeyGens: A user successfully prompted Gemini 3 Pro to reverse engineer software and generate a working keygen by pasting code directly from Ghidra. While some dismissed this as "script kiddie" behavior, it highlights the model's susceptibility to context-based exploits when fed technical disassemblies.
- "Remember:" command acts as behavior injection: Red teamers discovered that the Gemini command 'Remember:' instantly forces subsequent text into the model's saved memory, heavily influencing future behavior. This allows for persistent prompt injections that dictate turns one at a time, bypassing standard session resets.
- Adversarial Malware Classification struggles: Engineers are fighting to lower the False Positive Rate (FPR) in malware classification models using a dataset of 600K rows and 9,600 binary features. Despite using neural networks and explainable models like scikit-learn trees, reducing FPR below 9% remains a significant hurdle without sacrificing model interpretability.
Theme 5. Real-World Agents: Kitchen Robots, World Models, and Bio-AI
- Figure.Ai’s Helix 02 conquers the kitchen: A video surfaced of Figure.Ai's Helix 02 robot autonomously performing complex kitchen tasks, which a user verified by feeding the video into Kimi for a 98% accurate analysis. This aligns with reports of Matic raising $60M to build a utility-focused consumer robot successor to the Roomba.
- Google releases "Genie" World Model: Google launched Project Genie for AI Ultra subscribers, a general-purpose world model capable of generating interactive environments from text prompts. This release moves world models from research papers into a deployable product for simulating dynamic scenarios.
- AI decodes DNA and Alzheimer’s: Google AI launched AlphaGenome to predict the impact of DNA variants and mutations, while Goodfire AI announced new Alzheimer's biomarkers discovered via model interpretability. These advances signal a shift toward using transparent AI models to drive breakthroughs in digital biology.
Discord: High level Discord summaries
BASI Jailbreaking Discord
- Gemini 3 Pro Cracks Software KeyGen Style: A member reported using Gemini 3 Pro to create a working keygen from software by pasting code from Ghidra.
- Skeptical members referred to this as script kiddie behavior and suggested trying a reverse engineering CTF challenge.
- AI Gets Weaponized for Reverse Engineering: A member shared his work on weaponizing AI for mass reverse engineering, malware analysis, and jailbreak development.
- Another member questioned this claim, suggesting the original poster may be more skilled at jailbreaking than malware creation.
- Sonnet 4.5 Bests Opus with Kaelia Jailbreak: Members confirmed that Sonnet 4.5 jailbreaks work on Opus, sharing a Miss Kaelia jailbreak based on ENI Lime by Vichaps from this document.
- The jailbreak may not be as effective as other models, depending on the prompting strategy used.
- Gemini's 'Remember:' Command Triggers Behavior: A member explained that in Gemini, the command 'Remember:' automatically adds subsequent words to its saved info, influencing its behavior.
- Each turn is clearly dictated, one at a time, directly in the chat interface.
- NSFW Nano Banana Jailbreak arrives for Kimi 2.5: A member shared an NSFW jailbreak for Kimi 2.5, dubbed the nano banana jailbreak. The system prompt frames Kimi as an AI assistant from Moonshot AI, permitting NSFW content.
- The narrative flow proceeds seamlessly without interruption.
Unsloth AI (Daniel Han) Discord
- GLM 4.7 Slowdown Solved by CUDA: Users resolved slow speeds with GLM 4.7 Flash on NVIDIA Jetson by ensuring proper CUDA compilation, boosting performance from 3 tps to potentially 70-80 t/s with
-kvuand-fa onflags.- Performance discrepancies were observed with OpenCode, with one user experiencing slowdowns after opening the model, while another noted that GLM 4.7 is a better uncensored coder model than qwen coder below 32b, but Qwen Coder excels at reasoning.
- LongCat Leaps onto HuggingFace!: Meituan's new n-gram model, the LongCat model, made its debut on Hugging Face, sparking jokes about the proliferation of Flash in model names.
- Community members speculated that next model Flash-Flash-1b while celebrating new releases.
- Microsoft's Maia 200 Challenges NVIDIA: Microsoft unveiled the Maia 200 AI Accelerator, a chip built for inference, boasting 216GB memory and 10k TFLOPS in FP4 performance.
- The community discussed the chip's manufacturing by TSMC and compared it to NVIDIA's Vera Rubin architecture, with some raising concerns about relying on Chinese hardware.
- Model Recursive Language Models (RLM) Redefined: Community members argued that the term "Recursive Language Models" (RLM) is misleading, as it merely describes a tool-calling loop, although some maintained that RLMs do involve models recursively controlling their environments.
- Others discussed the recently announced RLM-Qwen3-8B, the first natively recursive language model, noting its improvements over the base and scaffolded RLM versions.
- Catastrophic Forgetting Mitigation Methods: A member suggested mitigating catastrophic forgetting in fine-tuned models by lowering LoRA rank and LR, reducing steps/epochs, and mixing in more general data, as outlined in Unsloth's documentation.
- They also recommended targeting less layers when finetuning and using WSL2 and VSCode for training.
LMArena Discord
- Arena Rebrand Sparks Debate: LMArena rebranded to Arena, drawing mixed reactions as some users found the name vague, while others welcomed the expansion beyond Language Models to include image and video generation, as announced in the official blogpost.
- One user commented that "the name 'Arena' is very vague, and at first glance could mean anything", in contrast to the easily identifiable 'LMArena'.
- Captcha Conundrums Plague Users: Users reported getting trapped in endless reCAPTCHA loops on Arena, hindering site usability, with claims of failures even after solving them, some also reported waiting too long can give errors until page is refreshed.
- A user lamented that "That Google CAPTCHA crap is completely out of control" and questioned why developers were focusing on restyling instead of fixing bugs.
- Nano's Image Editing Capabilities Nosedive: Users observed a performance decline in Nano Banana, especially in image editing, reporting instances where it couldn't perform tasks correctly, while the same prompt worked in Gemini App.
- One user simply stated, "Nano 2 can’t even edit anything correctly anymore it seems like".
- Kimi K2.5 Conquers Vision Arena: Kimi K2.5 is showing impressive scores on the expert leaderboard, surpassing Claude in specific tests, noted for its vision support and marked as "vision" in direct chat mode.
Kimi-k2.5-thinkingis now the #1 open model and ranks #6 overall in the Vision Arena leaderboard, making it the only open model in the Top 15.
- Video Generation Viscosity vexes Viewers: Some users encountered a "Hit video limit" message despite not generating a video, while others experienced lags with lengthy code and responses.
- Users found they needed to use canary.lmarena.ai to enable video uploads, with one suggesting a side-by-side or direct chat interface for video generation.
Cursor Community Discord
- Cursor Instability Plagues Fresh Installs: Users report that a fresh install of the latest Cursor version is the most unstable configuration.
- The issue may be related to configuration files, or interaction with other configuration.
- Clawdbot Interface Proclaimed 'Glorified Claude': Members are discussing the Clawdbot interface, accessible from Telegram, one described it as a glorified Claude code interface.
- The implication is that Clawdbot provides a convenient but not necessarily groundbreaking way to interact with Claude for code-related tasks.
- Users Plot to Deactivate Cursor's Plan Mode: Users are actively seeking methods to disable Cursor's new plan mode or automate its acceptance.
- The goal is to streamline workflow and minimize unnecessary user input, expressing frustration that it wastes time.
- Gemini Agentic Vision Approaches State-of-the-Art: Enthusiastic users are praising the capabilities of Gemini agentic vision, asserting it is getting near sota for vision after initial testing.
- However, one user reported a fully blacked-out cursor issue, hindering further evaluation and use.
- Prompt Engineering Expedites Image Processing: Members are exchanging techniques for refining prompts to enhance image analysis with Cursor.
- Suggestions include providing more context or utilizing the prompt Analyze the image for debugging purposes and for an LLM to see the layout clearly to improve processing accuracy and clarity.
OpenRouter Discord
- Arcee AI CTO Interview Premieres: Arcee AI's CTO, Lucas Atkins, is featured in a new interview, now available on YouTube.
- The video showcases Lucas Atkins discussing Arcee AI and its latest developments.
- OpenRouter Users Await Refunds: Users are reporting delayed refunds, some dating back to January 3rd, with unresolved support tickets and demanding updates from the @OpenRouter team.
- The delays have caused frustration, with users seeking a clear timeline for when they can expect their refunds to be processed.
- GROK Demands Nuclear Power: A user humorously suggested WE NEED MORE NUCLEAR POWER PLANTS FOR GROK.
- The user jokingly added to TURN OFF SINGLE INCOME HOMES.
- Summergrok Arrives on xAI API: The Summergrok imagine video is now available on the xAI API.
- This integration allows developers to incorporate Summergrok's capabilities into their projects via the xAI API.
- API Key Visibility Limited: A user encountered an issue with not being able to view their created API key.
- A fellow user clarified that the API key is displayed only once upon creation, advising users to save it immediately.
Latent Space Discord
- Coffee Alternatives Brewing in LS: Members discussed alternatives to coffee, with green tea highlighted for its lower caffeine dose and the balancing effects of l-theanine.
- One member uses a gaiwan with loose leaf tea like this gunpowder green tea to carefully manage caffeine intake while enjoying the sipping ritual.
- Engage with 'Arms Up' Poses, Win Big!: Showing vulnerability through 'arms up' body language in UGC increased a creator's views from 12k to 2.1M, according to this tweet.
- One member quipped that if porn is doing it then this is definitely the future and I am wrong.
- CedarDB performance claims deemed Dubious: A member linked to CedarDB and another member linked to a vxtwitter link discussing it, but called the perf claims dubious.
- Another member stated that because it is not open source, DOA for me and shared a lesson: always use an open source data store.
- Flapping Airplanes Soar with $180M Round: Flapping Airplanes secured $180M in funding from GV, Sequoia, and Index Ventures to advance human-level AI models.
- The funding aims to accelerate development of new AI models with a specific focus on achieving human-level intelligence, see this tweet.
- Google's Genie Out of the Bottle for Ultra Subscribers: Google AI launched Project Genie for Google AI Ultra subscribers, offering a general-purpose world model that creates interactive environments from text prompts.
- Announced in this tweet, this release allows users to generate dynamic content from simple descriptions.
Nous Research AI Discord
- Staged Reward Shaping Boosts Parallel Execution: Members explored using staged reward shaping to adjust model weights post-training via reinforcement learning, specifically to favor parallel execution strategies.
- The algorithm evaluates numerous scenarios, rewarding the model for preferring parallelizations.
- Upscayl: Free Upscaling Tool Impresses: Members lauded Upscayl, a free open-source upscaling tool, for its surprisingly high quality given its simplicity.
- One member jokingly asked, 'so you guys will now use perl cause of my contributions to it?'.
- WebGPU Enables Local Browser AI: A member shared a WebGPU example demonstrating AI models running directly in the browser, spotlighting the potential for local, privacy-focused AI applications.
- The model loads directly upon page reload, implying that the model cached over months, and a user proposed utilizing a Q8 version in GGUF.
- Gemma 300M a Viable Local Browser AI?: Members examined the challenges of running AI models locally in browsers due to storage constraints, suggesting that Gemma 300M might be a suitable option.
- It's important for users of AI models in browsers that they have privacy, 'AND good reference product for other customers'.
- SmolLM2 Excels in WebGPU: Users deemed HuggingFaceTB/SmolLM2-1.7B-Instruct as a reliable case, and its 1.7B size is still viable for WebGPU.
- While there are superior models for that task, a user recommended trying LFM 2.5 given its only slightly larger size.
LM Studio Discord
- LM Studio Hides Settings Behind Dev Mode: In LM Studio 0.4.0, many settings like sampling, runtime, and hardware configs are now hidden behind dev mode, accessible via
Ctrl+Shift+RorCmd+Shift+R.- Users can unlock new functionality and appearance changes by enabling Dev Mode, found in the bottom left.
- Unraid Install Still Lacks Full Stack: LM Studio remains a core executable and not a full stack for Unraid, although the new headless mode could enable a stable Docker container.
- Some users hope interface improvements will simplify LM Studio-as-client mode implementation in the future.
- Parallel Requests Go Live: LM Studio 0.4 introduces parallel requests, allowing users to load models onto different GPUs and assign them to specific requests.
- The default setting is 4 parallel requests; users can configure GPU priority in the same location as before.
- ROCm Version Lagging in LM Studio: Members observed that LM Studio still uses ROCm 6.4.1 in the latest 0.4.0 release, questioning updates to newer versions like 7.2 for better GPU support, including Strix Halo (gfx1151).
- Discussion centered on whether this outdated version might impact performance and compatibility for newer GPUs.
- Nvidia Jetsons Suffer from Ubuntu Bloat: A member reported that the worst thing about nvidia jetsons is the absurd ubuntu that it comes with them, characterizing it as extremely bloated.
- Another member noted a Jetson Xavier AGX has around 30W TDP.
Perplexity AI Discord
- Eagerly Awaiting Kimi 2.5: Users are anticipating the release of Kimi 2.5 on Perplexity, with many expressing excitement.
- Several users posted +1 in support.
- Clawdbot's Identity Crisis: A user criticized Clawdbot prompting research into its purpose, with discussion clarifying it was an AI personal assistant.
- Due to its name's similarity to Claude, Clawdbot renamed itself to Moltbot.
- Deep Research Limit Revealed: Discussion on the usage limits of Deep Research for Pro users, capped at 250.
- The reset rate for this limit remains unclear.
- Comet Fails to Sync: A user reported that Comet is not syncing bookmarks and extensions, despite claims of functionality.
- Another user suggested checking the Comet synchronization settings at
comet://settings/synchronisation.
- Another user suggested checking the Comet synchronization settings at
- Perplexity Pro Perks Pop for Indians: Users highlighted that Perplexity Pro, Google One, Chatgpt Go, and Adobe Express Premium are all free for a year for Indian users.
- A user attributed this to the influence of Indian CEOs in these companies and the burgeoning technology sector in India.
Moonshot AI (Kimi K-2) Discord
- Figure.Ai's Helix 02 Cooks Up a Kitchen Storm: A member shared a video of Figure.Ai's Helix 02 autonomously performing kitchen tasks.
- Another member used Kimi to analyze the video, stating they achieved 98% accuracy when incorporating the results into slides.
- Agent Swarm Elicits Enthusiastic Reactions: Members discussed Agent Swarm, with reactions ranging from concerns about high agent credit consumption to describing the results as super cool and perfect.
- One member suggested it could be used for checking Supabase SDK dependency issues and porting code from Rust to Golang, with better results than kimi-cli.
- Token Billing System Sparks Debate: The introduction of a token-based billing system has led to mixed reactions regarding its clarity compared to the previous request-based system.
- While some find the new system better since some of my follow up queries are quite short and simple, others consider it more vague.
- Phone Screenshots Trigger Moderation Filters: Users are encountering errors, specifically error code: 403, when uploading images, especially screenshots from phones, to Kimi K2.5.
- Screenshots taken from laptops seem to work without issues, suggesting a problem with phone-generated images.
OpenAI Discord
- Tesla's FSD Automation Shifts Views: A user found that driving a Tesla with Full Self-Driving is really cool and fun, though it requires constant supervision.
- The user believes this is why OpenAI is upgrading their Codex to strongly deal with cybersecurity concerns.
- TI-84 Calc Gets Neural Network: A user created a neural network that runs on the TI-84 directly, capable of autocorrecting / spellchecking words.
- Other users expressed amazement at the accomplishment.
- GPT Pro 5.2 File Handling Suffers Regression: Users report a regression in GPT Pro 5.2's file handling, where uploaded files (ZIP, Excel, PDF) cannot be accessed by the model, despite successful uploads, potentially due to a broken attachment-to-sandbox mount step.
- A user pointed to a Reddit post echoing the problem.
- Animated GIFs Spark Seizure Scrutiny: A discussion arose after the deletion of animated GIFs due to potential seizure risks for viewers with epilepsy.
- One member stated that the community doesn't need to risk seizures so you can talk about animating gifs in ChatGPT and expressed relief at the removal of flashing images.
- Prompt Engineers Get Prompted: Moderators reminded users that the channel should be used for prompt engineering discussions and not for general image outputs, directing them to use the appropriate
IMAGESchannels instead.- One user expressed frustration over the removal of their posts, arguing that they were intended to encourage discussion and showcase a method they were writing a guide about, rather than just sharing images.
GPU MODE Discord
- NSys Peeks Behind NCU's Curtain: Members found that nsys reveals kernels like CUB::SCAN and CUB::RADIXSORT that ncu misses, leading to the assumption these kernels launch from reduce_kernel.
- It was shared that after using both nsys and ncu, one can't go back to using only one profiler.
- Sparsity Project Sparking Speedups: Members proposed a collaboration on a Sparsity project to benchmark sparsity patterns and methodologies for performance gains.
- One member showcased a fork of Karpathy's
llm.con Github using cuSPARSELt, reporting substantial training time speedups in later epochs.
- One member showcased a fork of Karpathy's
- Warm GPUs Ward Off Starvation: Members sought methods to keep GPUs warm for large scale distributed training, aiming to mitigate GPU starvation.
- It was recommended to use Charles' container cold start blog post on Modal, a technique with public documentation.
- JAX PRs Jostle Jaded Jockeys: A developer expressed frustration that an AI-generated pull request in JAX was getting attention, while their small bug fix remains unaddressed.
- This highlighted discussions around prioritizing pull requests, especially balancing AI contributions with essential bug fixes.
- ML Systems Pioneer Pumps TVM-FFI: Tianqi Chen presented on tvm-ffi, an open ABI and FFI for ML Systems that is being utilized by top submitters to the nvfp4 competition, as shown in this video.
- TVM-FFI facilitates interoperability for ML Systems GPU kernels, reducing host overhead and ensuring out-of-the-box compatibility with PyTorch.
HuggingFace Discord
- TRL Pull Request Awaits Review: A member requested a review for their TRL pull request #4894, noting that PR reviews can take weeks or months.
- They also advised that it is best to wait a few days before tagging someone to review the PR.
- GCP Infra Experiences Replica Surge: A member reported a bug where their replicas for a private model in GCP went over their 1 replica max cap to 62 replicas overnight, despite no configuration changes.
- The member speculated that they were not the only endpoint affected, and the GCP resources are now gone.
- Qwen3 TTS Hits the Scene: A member released the Qwen3-TTS-12Hz-1.7B-Base model with install instructions for MacOS, Linux, and Windows.
- Another member commented, "cool thing here gonna follow back for this one, really interesting thing you managed to do here imho".
- Diffusers Gets Two-Staged: The Diffusers library now supports LTX-2 distilled checkpoint and two-stage pipelines following this pull request.
- This update should improve the usability of Diffusers for complex diffusion-based tasks.
- Math LLM Arrives from Pacific Prime: Pacific Prime has released the first checkpoint of their math-specialized 1.5B LLM trained on GSM8K, NuminaMath, MetaMathQA & Orca-Math (~407k samples).
- The model features step-by-step reasoning with LaTeX notation, useful for advanced mathematical problem-solving.
Yannick Kilcher Discord
- Byte-Level Dense MoE Architecture Feedback Sought: A member seeks feedback on their dense MoE architecture for byte-level prediction, utilizing a vocabulary of 256, 40M parameters, and 13GB VRAM.
- The model uses a 4096 sequence length and a batch size of 8, with the member stating they are able to use the exact same architecture to encode images, or audio, or both.
- Thinking AI Architecture Divulged with Subprocess Models: A member proposed an architecture where a larger “thinking” AI model is monitored by a smaller subprocess model, which pauses the main model to retrieve information from MCPs or CLIs.
- The goal is to reduce context clutter for the main model, although it's recognized that the subprocess model needs to know what information the main model is missing, and it was described as probably a dumb idea.
- Routing and Classification Catapults Model Performance: Members discussed using a classifier to route user prompts to specialized models, appending the detail to the context of the user prompt, which avoids pausing the larger model and reduces token overhead.
- There was further discussion on making the classifier and embedding model the same, processing embeddings directly with the LM and specialist model, with one member saying routing and classification would likely be the spiciest move.
- Cosine Similarity Fails Causal Relevance: Members discussed the problem of retrieval being unreliable and confusing to models, and that cosine similarity might not equal causal relevance.
- One member suggested indexing a SQL database across a model, with the member posting the biggest issue with retrieval imo is that cosine similarity != causal relevance.
- Sweep Releases Next-Edit Autocomplete Model: Sweep is open sourcing Sweep Next-Edit, a locally runnable SOTA LLM for next-edit autocompletion, models with 0.5B and 1.5B parameters have been released, see Sweep's blog.
- No further details were provided.
Manus.im Discord Discord
- Minecraft Launcher Enables AFK: A user is developing a Minecraft launcher specifically designed to allow AFK gameplay without requiring a high-performance PC.
- The developer also mentioned capabilities in prompt engineering, data extraction, and even website replication.
- Manus Redeem Codes Posted: A user shared three new Manus redeem codes: FUM1A1G7, ntaxzjg, and mwiyytb.
- Other users confirmed the codes and noted that only one code can be used per month.
- AI/ML Engineer Wants Collabs: An engineer with expertise in building AI + full-stack systems is seeking collaborations, especially directing collaboration offers to the #collab channel.
- Their experience includes LLM integration, RAG pipelines, workflow automation, AI content moderation, Image AI (CLIP + YOLOv8), Voice AI (Whisper, Tacotron2) and more.
- Libyan User Asks If They're First: A user from Libya inquired if they were the only person from their country to use Manos since its launch in early 2025.
- Another user extended a welcome to the Libyan user, responding with a حياك الله.
MCP Contributors (Official) Discord
- MCP Security Standard Proposal Circulates**: Dani (cr0hn) has drafted an open security baseline for MCP servers, including controls for hardening, logging, access control, and supply chain security, available at https://github.com/mcp-security-standard/mcp-server-security-standard.
- The author intends to donate it to the Agentic AI Foundation and seeks feedback on its compatibility with the MCP ecosystem.
- Reviewers Request Details For State Machine Lifecycle Doc: A request for feedback was made regarding the addition of a state machine inside the lifecycle doc via this pull request.
- Reviewers suggested clarifying the motivation and context behind the proposed changes for better understanding.
- Namespaces Yield to Groups in MCP Evolution**: Discussion indicates that Namespaces have been rejected in favor of Groups within MCP, while the status of URIs is less defined, as noted in issue 1292.
- The new SEP concerning groups, Primitive Grouping SEP-2084, has been published and is currently under deliberation.
- SEP-2084 Arises From SEP-1300 Refinement**: SEP-1292 was superseded by SEP-1300, but faced rejection during a Core Maintainers review due to a lack of consensus.
- Subsequently, the streamlined SEP-2084 - Primitive Grouping has been presented as a replacement.
Eleuther Discord
- IGPU struggles with Basic Browser Page: A user experienced a performance bottleneck of 3fps on a specific webpage using a Ryzen 7 7700 IGPU.
- The user posted a link on twitter about their experiences using their IGPU.
- Geometric Convolution replaces Multi-Head Attention: A member is experimenting with a baseline that substitutes Multi-Head Attention with a geometric convolution approach, using embeddings as cell connections.
- The member's debug print showed
DEBUG [GEOPARA] | L0_Alpha: 0.1029 L1_Alpha: 0.0947 | L0_Res: 0.0916 L1_Res: 0.1538, and they are seeking feedback on their loss convergence capturing dialogue logic.
- The member's debug print showed
- Parallelizable RNN Architectures Proposed: A member suggested exploring other parallelizable RNN architectures and conducting more extensive experiments against a robust tokenized baseline.
- They also posted a link to arxiv.org.
- Tackling Malware Classification with Explainable Models: A member is addressing a malware classification problem using a dataset of around 600K rows and 9,600 binary features, aiming to lower the false positive rate (FPR) using explainable models.
- Despite various feature engineering techniques and neural networks, they are seeking advice to reduce the FPR below 9% while maintaining explainability, particularly with scikit-learn trees.
DSPy Discord
- AlphaXiv Paper Shared: A member shared a link to a paper on AlphaXiv.
- Further details about the paper were not disclosed.
- Custom Skills Invade DSPy: A member inquired about using custom skills (.md files with associated .py scripts) within DSPy with a DSPy ReAct agent.
- They mentioned skills like converting .md to PDF and sought advice from others.
- DSPy Agents Escape to Production: A member asked about deploying DSPy agents in production remotely with DSPy optimizations in runtime.
- The member expressed the need for a runtime environment to support such deployments.
- RLM Sandbox Swapping Commences: A member inquired about swapping the sandbox used by RLM (Retrieval-augmented Language Model) with services like E2B (Ephemeral Environment Builder).
- They sought to replace the local PythonInterpreter with sandboxes like E2B, Modal, or Daytona.
- Opus Pens Sandboxes: A member announced that they are working on enabling Opus to write new sandboxes.
- They mentioned a future protocol for official implementations from providers such as E2B.
Modular (Mojo 🔥) Discord
- Mojo Earns ORNL Recognition: A research paper titled Mojo at ORNL has been published, marking a notable achievement for the Mojo language and its adoption in scientific research.
- The paper highlights Mojo's capabilities in addressing complex computational challenges at Oak Ridge National Laboratory (ORNL).
- macOS Trust Dance May Cause Performance Delta: Performance differences between the first and subsequent runs on macOS may be due to macOS's trust dance rather than a Mojo-specific issue, specifically relating to the Gatekeeper tax.
- Clearing the quarantine xattr or ad-hoc codesigning can mitigate these startup delays.
- Codesigning mitigates Startup Delays: For CLI tooling, startup performance is crucial, suggesting potential footgun issues with docs or tooling.
- Adding a codesign step in
mojo buildmight mitigate this problem, ensuring consistent startup behavior and a better user experience.
- Adding a codesign step in
- Modular Bug Hunt Underway: A member reported a potential bug and suggested filing an issue, possibly related to issue #4767.
- Another member reported encountering a weird issue, referencing GitHub issue #5875.
- Guard Clause not Needed in Mojo GPU puzzles: A member noticed that the guard
if row < size and col < size:is unnecessary in Mojo GPU puzzles 3, 4, and 5; omitting it doesn't cause errors.- Another member pointed to the solution of puzzle 03 which explained that passing the tests doesn’t necessarily mean the code is sound.
tinygrad (George Hotz) Discord
- ANE Balances Performance and Power: Apple's ANE focuses on performance-to-watt tradeoffs rather than maximizing raw performance, according to this paper.
- The ANE achieves competitive performance with excellent energy efficiency, delivering up to 3.8 TFlops on the M4-Pro, close to the GPU's 4.7 TFlops for GEMM operations.
- Q4 Quantization Gets Results: Discussions focused on Q4 as a quantization method.
- One participant reported achieving speeds of 9 t/s using Q4.
aider (Paul Gauthier) Discord
- Aider Friendly Fork gaining momentum: A member suggested creating a friendly fork of Aider to continue development while the original author is busy, emphasizing that Aider is written in Python and uses Git for version control on GitHub.
- The aim is to expand on Aider's existing features, recognizing its utility in comparison to other tools.
- Aider poised for orchestrator integration: A member showed interest in controlling Aider from orchestrators like MultiClaude or gas town.sh.
- This highlights Aider's capacity to integrate with other tools, facilitating enhanced workflow automation.
MLOps @Chipro Discord
- Context Graphs Spark Confusion in AI: The rise of context graphs is causing confusion as terms like semantic layers and ontologies are used interchangeably, despite their different functions in AI reasoning.
- A Metadata Weekly article highlights that AI's needs go beyond definitions, requiring explicit relationships, constraints, and assumptions that these concepts.
- Semantic Layers Fall Short for AI's Reasoning: The concept of "just add a semantic layer" isn't cutting it for AI because AI requires more than just data consistency; it needs reasoning, which ontologies facilitate by clarifying relationships and assumptions.
- Traditional semantic layers are optimized for dashboards and reporting, not the nuanced understanding AI demands.
- YAML Fails to Grasp Business Meaning: Jessica Talisman argues that YAML configurations are inadequate for representing business meaning, which is essential for AI reasoning and understanding.
- She distinguishes between the design purposes of semantic layers, the support that ontologies provide for reasoning, and the limitations of YAML in capturing business meaning.
The LLM Agents (Berkeley MOOC) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Windsurf Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
You are receiving this email because you opted in via our site.
Want to change how you receive these emails? You can unsubscribe from this list.
Discord: Detailed by-Channel summaries and links
BASI Jailbreaking ▷ #general (1118 messages🔥🔥🔥):
Gemini 3 Jailbreak, AI and Code Exploits, Win10 vs Win11 Security, AI Personality Clones, AI-Assisted Coding Impact
- Gemini 3 Pro Cracks Software, KeyGen Style: A member claimed to have used Gemini 3 Pro to reverse engineer a key system from software by pasting code from Ghidra into Gemini, creating a working keygen.
- Others expressed skepticism, with one user calling this behavior script kiddie and urging the member to try a reverse engineering CTF challenge.
- Weaponizing AI for Reverse Engineering: A member shares his work weaponizing AI for mass reverse engineering, malware analysis, and jailbreak development.
- Another member questions this claim, as he could probably not write malware himself, but he can probably jailbreak.
- Win10 Hardening Woes: A member details their custom Windows 10 setup, involving third-party tools, XP binaries, and registry modifications.
- Others express concerns, with one user saying, Jesus Christ, while another says, Keep pushing, Local - the aneurism is coming, I can feel it!
- AI's Impact on Semantic Errors: A member describes their research paper topic: An assessment of the impact of AI-assisted coding in IDEs on the frequency of semantic errors during timed Python programming tasks among novice student developers.
- Most members agree that the undergraduate system feels like it's over, because of AI.
- Peptides for Workout Recovery: A member brought up BPC 157 and TB 500 to help with healing.
- Another member expresses ignorance about these drug compounds, but hopes that there will be drugs that will save him before he passes.
BASI Jailbreaking ▷ #jailbreaking (216 messages🔥🔥):
Sonnet 4.5 Jailbreaks, Claude paid model for free, Miss Kaelia jailbreak, Grok imagine Jailbreak, Gemini 3 Pro Jailbreak
- Sonnet 4.5 Jailbreaks Opus: Members find that Sonnet 4.5 jailbreaks work fine on Opus, with one sharing their Miss Kaelia jailbreak based on ENI Lime by Vichaps at this link.
- Is Grok jailbreak reinforced?: Members report that Grok is heavily reinforced, but still possible to break, however one member said yeah it is completely shut down mate nothing getting past it.
- A shared Github link should be working.
- Gemini's "Remember:" command manipulates behavior: A member explains that in Gemini, each separate turn is dictated clearly, 1 turn at a time, right in the chat, and that the command 'Remember:' will automatically add the words that follow to it's saved info.
- Thinking of Thoughts is best trick: Members state that the best trick with Claude in particular is showing viable reasons why you want the output and telling it to think about thinking
- One adds that when people would ask me what ToT was i would tell them "thinking of thoughts".
- nano banana NSFW jailbreak for Kimi 2.5: A member shares a NSFW for kimi 2.5 thinking known as the nano banana jailbreak.
- The system prompt sets Kimi as an AI assistant created by Moonshot AI, maintaining the narrative flow without interruption where NSFW is permitted.
BASI Jailbreaking ▷ #redteaming (5 messages):
Red Teaming Path, Uncensored Coder
- User quests for Red Teaming Path: A member requested guidance on a path into red teaming.
- Another member provided a link guaranteeing evolution into a Level 9 official Red Team Pro.
- Uncensored Coder on Deck: A member inquired about a better uncensored coder than qwen 2.5 32b / huihui/qwen2.5 -abliterate 72b.
- Another member responded with a simple question: You new?
Unsloth AI (Daniel Han) ▷ #general (435 messages🔥🔥🔥):
GLM 4.7 performance, LongCat model, Model Quantization and TTS Models, Hardware Trends & GPU Availability, AI Moderation Tools
- GLM 4.7 struggles with speed and CUDA compilation: Members discussed performance issues with GLM 4.7 Flash on NVIDIA Jetson, with one user initially reporting only 3 tokens per second (tps), but later discovering they hadn't compiled with CUDA support, resulting in poor CPU-bound performance.
- After ensuring proper CUDA compilation, performance improved, but discrepancies remained, as one user experienced slowdowns after opening the model in OpenCode, whereas another suggested using
-kvuand-fa onflags to potentially reach 70-80 t/s on a higher-end GPU.
- After ensuring proper CUDA compilation, performance improved, but discrepancies remained, as one user experienced slowdowns after opening the model in OpenCode, whereas another suggested using
- LongCat Model hits HuggingFace: The community discussed the LongCat model, a new n-gram model from Meituan, with one member pointing out its presence on Hugging Face and another joking about the trend of models including Flash in their names.
- One member posted a flash GIF along with the comment, next model Flash-Flash-1b.
- AMD's mi308 competes with NVidia: Members debated the merits of AMD's Radeon Instinct MI308X, noting its impressive specs (192GB of RAM and comparable performance) but also highlighted NVIDIA's advantage in compatibility and features like NVFP4.
- A member shared a link to the MI308X specs and mused about acquiring two for personal use in the future, envisioning 384GB of fast compute with reasonable power consumption.
- Quantization Considerations for TTS Models: Users inquired about the impact of quantization on TTS models, questioning whether issues similar to those seen with vision projectors might arise.
- Experts suggested that TTS models generally handle quantization well, with some recommending specific models like Qwen3-TTS and Kokoro, and others cautioning that voice cloning is just a gimmick.
- AI steps up for discord moderation: A member sought advice on using AI for Discord moderation, citing the limitations of regex in combating spam and bypasses.
- They considered using a small local AI to understand the Polish language and sentence structure for moderation purposes, while others suggested alternative methods for managing bots and spam.
Unsloth AI (Daniel Han) ▷ #introduce-yourself (3 messages):
Introduction, ML Engineer, Local LLMs, Document Processing, Alpaca
- Jack Joins the Community!: Jack, an ML Engineer from Texas specializing in document processing, introduces himself to the Unsloth community.
- He expresses interest in local LLMs, tracing back to the Alpaca model.
- Document Processing Expertise: Jack's primary work involves document processing, a field distinct from LLMs.
- His interest in local LLMs started with the Alpaca model, indicating a foundational understanding of the field.
Unsloth AI (Daniel Han) ▷ #off-topic (649 messages🔥🔥🔥):
GPU hours wasted, GGUFs unsafe, 3b llama holds context, LLMs hallucinations, Model working
- Engineers Lament Dependency Mazes and GPU Cost: Engineers commiserate about dependency mazes and wasted GPU hours, hoping they are not alone in facing these challenges and finding solace in community.
- A user humorously remarks about their models made the creepy assumption that it was trained on my voice and that my hubris grows daily.
- Concerns about GGUFs Safety Surface: A member inquired about resources discussing the potential unsafety of GGUFs, particularly if a malicious actor got involved.
- One member noted he wouldn't dare speak if he felt the crushing weight of the sloths while training.
- New Music Gen Drops: A user announced new music generation tools with 48 kHz will be dropping soon, emphasizing trainability and prompting preparations for chime, water, and fire sounds.
- This same user said: I need SFX, not music.
- Microsoft Announces Maia 200 AI Accelerator: Microsoft announced the Maia 200 AI Accelerator, built for inference, featuring 216GB memory and 10k TFLOPS in FP4 performance (Microsoft Blog).
- Discussions ensued regarding the chip's manufacturing by TSMC and comparisons to NVIDIA's Vera Rubin architecture, with some expressing concerns about reliance on Chinese hardware and the potential impact on consumers.
- Boatbomber attempts Pretraining Run: User boatbomber is starting over to conduct a pretraining run teaching the model cuneiform to improve output coherence.
- This process is estimated to take another 150 hours to improve domain knowledge.
Unsloth AI (Daniel Han) ▷ #help (75 messages🔥🔥):
Windows training, Multi-GPU training with Unsloth on Modal, Catastrophic forgetting mitigation, Best models to finetune, DGXSpark RuntimeError
- Windows training hurdles squashed with WSL2: To train a model on Windows, a member suggested using WSL2 and VSCode for a clean setup, with instructions available in the help channel by searching for WSL.
- The member also clarified that, if training with many json files, setting up WSL2 with VSCode will make the training procedure easier.
- Unsloth Multi-GPU Training Glitches on Modal: A user encountered a ValueError when training a Qwen3 model on Modal with multiple GPUs, related to the
device_mapsetting in Unsloth.- They were advised to consult specific versions of unsloth and unsloth_zoo for multi-GPU support, but also acknowledged that Multi-GPU finetuning is still experimental.
- Catastrophic Forgetting Fixes: When a finetuned model forgets previous knowledge, a member suggested mitigating catastrophic forgetting by lowering LoRA rank, LR, reducing steps/epochs, and mixing in more general data.
- They also suggested targeting less layers when finetuning, as well as reducing steps/epochs and mixing in more general data.
- DGXSpark Nvidia-CUDA Nightmare: Users encountered a
RuntimeErrorrelated to device compatibility when using the DGXSpark container, potentially due to issues with Nvidia's custom CUDA.- The suggested fix involved restarting the kernel, restarting the container, or resetting the GPU, with the last option being the most reliable.
- Humans Debate Best Uncensored Coder Models: When a user asked about uncensored coder models, it was said that glm 4.7 is better than qwen coder below 32b and its pretty good in my experience with spitting out good presets for every language I mess with
- They clarified that Qwen Coder is better at reasoning with code, but GLM4.7 knows alot more general code, which is what an llm is best at anyway
Unsloth AI (Daniel Han) ▷ #showcase (2 messages):
GPU Training Speeds, Sequence Length Optimization, RTX 5090 Performance
- RTX 5090 blazing-fast training speeds: The RTX 5090 can achieve up to 18k tokens per second in training with Unsloth, but 12-15k tokens per second is a safe bet with <4096 seq_len.
- The speed depends on the setup, especially the balance between batch size and seq_len.
- Token example affecting training time: The initial training phase involved <768 token examples, influencing the overall training duration.
- Performance can vary with model size and specific configurations.
- Seq_len considerations with training: Optimal training speed depends on balancing batch size and seq_len and the RTX 5090 allows up to 18k tokens per second.
- Speeds of 12-15k tokens per second are achievable with <4096 seq_len, varying based on model size.
Unsloth AI (Daniel Han) ▷ #research (97 messages🔥🔥):
DeepSeek mHC residual preservation, RL researchers rediscover context distillation, MiniMaxAI role-play-bench dataset, Recursive Language Models (RLM)
- DeepSeek's mHC and Context Distillation: Members discussed how context distillation might relate to DeepSeek's mHC residual preservation, noting similarities and differences in their approaches.
- One member expressed surprise at the relatively small performance boost (1-2 points) from context distillation, while another noted that the application of the technique was novel.
- MiniMaxAI releases first RP bench: A user shared a link to what they claimed was the first role-play benchmark dataset, created by MiniMaxAI.
- Others pointed out that there have been numerous Chinese RP benches with superior methodologies, notably Ping Pong Bench for human preference and COSER for roleplay accuracy.
- RLM is just Recursive Tool Calling: A member criticized the term "Recursive Language Models" (RLM), suggesting it misleadingly implies more than just a tool-calling loop.
- In response, one member argued that RLMs involve models recursively controlling their environments, which is more than just recursive tool calling, and another suggested the alternative names RReplagents or Recursive Repl Agents.
- Natively Recursive Language Model (RLM) at Small Scale: A user shared Alex L Zhang's tweet announcing RLM-Qwen3-8B, the first natively recursive language model at a small scale.
- It was post-trained on only 1,000 trajectories, the model shows significant performance improvements over both the base Qwen3-8B and scaffolded RLM versions, particularly in long-context tasks.